
This is again a big win on the red team at least for me. They developed a “fully open” 3B parameters model family trained from scratch on AMD Instinct™ MI300X GPUs.
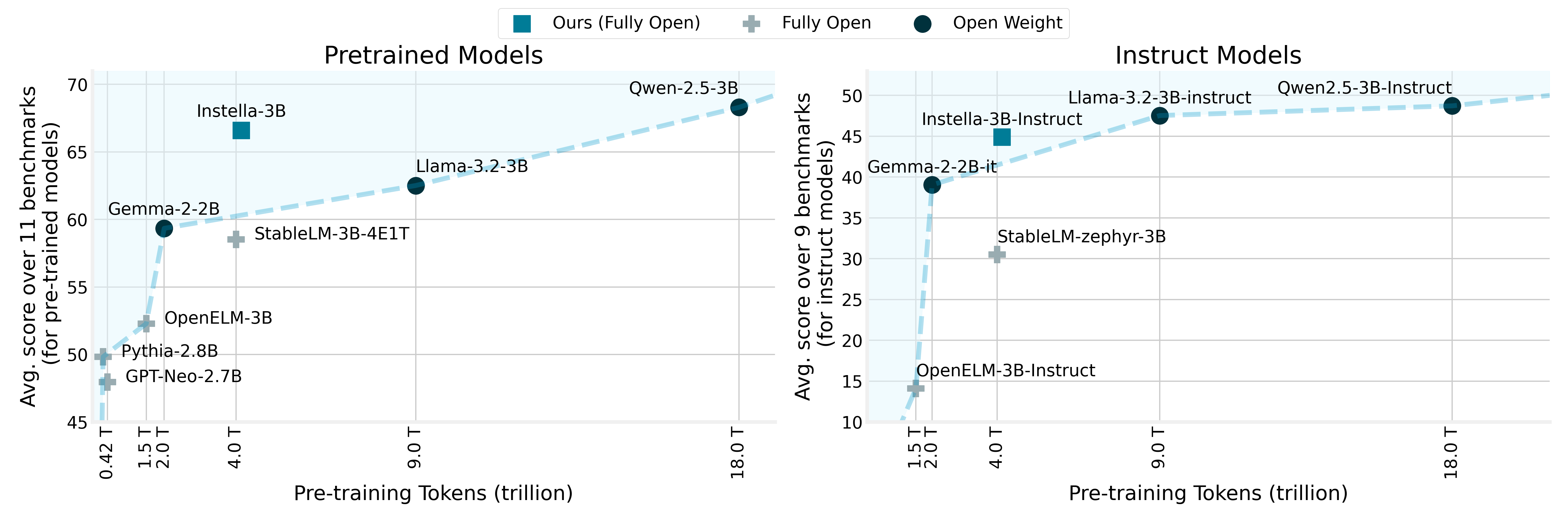
AMD is excited to announce Instella, a family of fully open state-of-the-art 3-billion-parameter language models (LMs) […]. Instella models outperform existing fully open models of similar sizes and achieve competitive performance compared to state-of-the-art open-weight models such as Llama-3.2-3B, Gemma-2-2B, and Qwen-2.5-3B […].
As shown in this image (https://rocm.blogs.amd.com/_images/scaling_perf_instruct.png) this model outperforms current other “fully open” models, coming next to open weight only models.
{kind=link}
A step further, thank you AMD.
PS : not doing AMD propaganda but thanks them to help and contribute to the Open Source World.
Nice. Where do I find the memory requirements? I have an older 6GB GPU so I’ve been able to play around with some models in the past.
No direct answer here, but my tests with models from HuggingFace measured about 1.25GB of VRAM per 1B parameters.
Your GPU should be fine if you want to play around.
LMstudio usually lists the memory recommendations for the model.
Following this page it should be enough based on the requirements of qwen2.5-3B https://qwen-ai.com/requirements/