
{kind=link}
Hi everyone, I’ve been building my own log search server because I wasn’t satisfied with any of the alternatives out there and wanted a project to learn rust with. It still needs a ton of work but wanted to share what I’ve built so far.
The repo is up here: https://codeberg.org/Kryesh/crystalline
and i’ve started putting together some documentation here: https://kryesh.codeberg.page/crystalline/
There’s a lot of features I plan to add to it but I’m curious to hear what people think and if there’s anything you’d like to see out of a project like this.
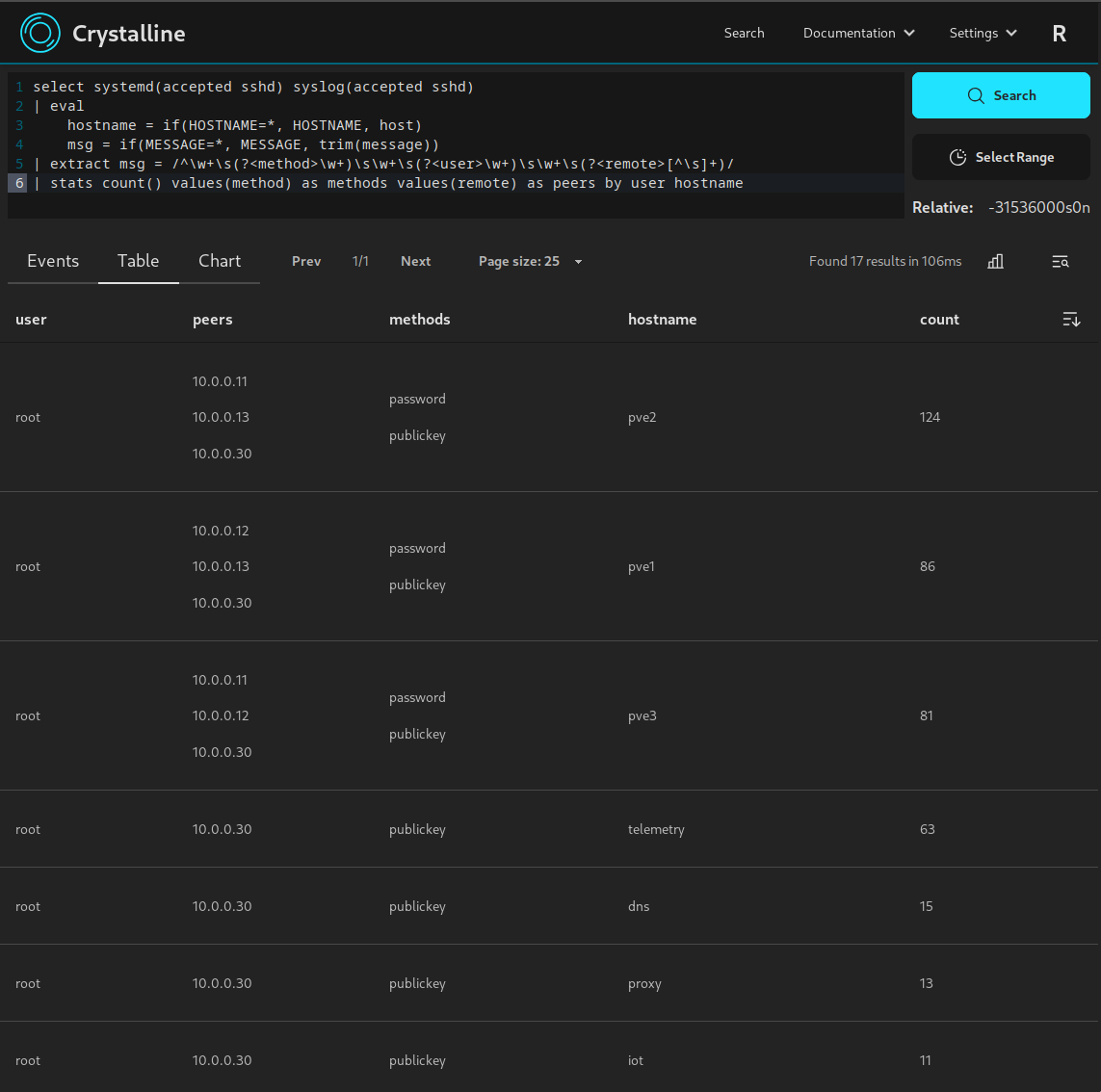
Some examples from my lab environment:
events view searching for SSH logins from systemd journals and syslog events:

counting raw event size for all indices:

performance is looking pretty decent so far, and it can be configured to not be too much of a resource hog depending on use case, some numbers from my test install:
- raw events ingested: ~52 million
- raw event size: ~40GB
- on disk size: ~5.8GB
Ram usage:
- not running searches ingesting 600MB-1GB per day it uses about 500MB of ram
- running the ssh search examples above brings it to about 600MB of ram while the search is running
- running last example search getting the size of all events (requires decompressing the entire event store) peaked at about 3.5GB of ram usage
Thanks! it’s definitely got a way to go before it’s remotely competitive with any of the enterprise solutions out there, but you make a good point about having comparisons so I’ll look at adding it.
I’m basically building it to have a KQL/LogScale/Splunk/Sumologic style search experience while being trivial to deploy (relative to others at least…) since I miss having that kind of search tooling when not at work; but I don’t want to pay for or maintain that kind of thing in a lab context. It creates a Tantivy index per day for log storage (with scoring and postings disabled for space savings).
In the end my main goal of the project was as a vehicle to get better at programming with, and if I get a tool I can use for my lab then that’s great too lol.
You’re nailing your goal then!
I would still steer you slightly towards documenting your architectural decisions more. It’s a good skill to have and will help you in a long run.
You have dozens of crate dependencies and only you know why they are in there. A high-level document on how your system interconnects and how the algorithms under the hood work will be a huge help to anyone who comes looking through your source code. We become better programmers not by reading the source code, but by understanding what it actually does.
Here’s a random trivia: your server depends on trust-dns-resolver. Why? Why wasn’t the stock resolver enough? Is that a design choice or you just wanted to have fun? There is no wrong answer but without the design notes it’s hard to figure your intent.
More good points, thank you! for trust-dns-resolver that’s a relic from a previous iteration that had polling external sources and needed to resolve dns records. Since i haven’t gotten around to re-implementing that feature it should be removed. As for why - I actually needed to bring my own resolver since the docker container is a scratch image containing only some base directories and the server binary so there isn’t any OS etc to lean on for things like dns; means that the whole image is ~15.5MB which is nice and negates a whole class of vulnerabilities.
Understood that your actual point is to document this stuff and not answer the trivia question though
That’s a good point. Mind that in most production environments you’d be firewalled rather hard (especailly when it comes to logs processing which oftentimes ends up having PII). I wouldn’t trust any service that tries to use DoT or DoH in there that I couldn’t snoop on. Many deployments nowadays allow you to “punch” firewall holes based on the outgoing dns requests to an allowlisted domain, so chances are you actually want to use the glibc resolver and not try to be fancy.
That said, smaller images are always good in my book!
Oh I wasn’t using it as a full recursive resolver - just reading the resolv.conf set by docker and sending requests