

2·
4 months agoI don’t know if it’s your cup of tea, but Neovide provides smooth scrolling at arbitrary refresh rates. (It’s a graphical frontend for Neovim, my IDE of choice.)
Programmer in NYC
I don’t know if it’s your cup of tea, but Neovide provides smooth scrolling at arbitrary refresh rates. (It’s a graphical frontend for Neovim, my IDE of choice.)
For some more detail see https://dev.to/martiliones/how-i-got-linus-torvalds-in-my-contributors-on-github-3k4g
Oh right, there are some particular things that are helpful for a deeper language understanding.
Type classes and algebraic types are for sure standout features of Rust that make it better than most languages. Much of my experience before Rust was Typescript, but I have some background in Haskell so I was fortunate to have a head start on these concepts. I haven’t done any Rust interviews - my current role switched from Haskell to Rust after I joined. So I don’t know what interviewers are asking.
None of the prior languages you listed use manual memory management (which was the same for me). And even if you have that background, Rust does some things differently. (Although from what I understand explicitly codifies a number of ideas that experienced C++ devs have in their heads as “good practice”.) I think you’ll want to study up on how memory works. One of my favorite resources for this is Logan Smith’s Youtube channel. Those videos get me thinking about how this stuff I take for granted really works. The first two Rust videos on there, Use Arc Instead of Vec and Choose the Right Option are good ones to watch. Even if you opt not to use Arc<[T]> or Box it’s useful to understand how those differ from Vec and String.
Closures are weird in Rust, and are worth understanding. You have to choose between Fn, FnMut, and FnOnce. Plus there is the move keyword. I love the post Finding Closure in Rust for explaining what’s going on there. (It takes the implement-your-own-version approach which is a genre where I’ve incidentally seen some other gems, like Implementing a simple Promise in Javascript, and The Git Parable for understanding how git really works.)
Another area that is helpful to study is Rust’s implementation of async. It is similar to async as you’ve seen it before, but also different. For example in Javascript when you call an async function like, say, fetch it dispatches network requests right away. But in Rust a Future does not do anything until you call await on it. Learning about async leads into understanding of some more general language features. At the shallower end you learn about functions that return types based on trait, like impl Future or Box> because Future types often can’t be named directly so you have to describe what trait they implement instead. (This is very similar to how you work with functions that return closures.) At the deeper end you learn about working with Pin. You can get a deep dive on that in Pin and suffering by fasterthanlime. All of that guy’s posts are useful, but they are deep plunges so it can take some motivation to read them.
Since I seem to be recommending people to learn from I’ll add Mara Bos’ blog. She’s the Rust Library team lead. Her blog gets into some of the nitty-gritty stuff that gets you thinking about the language on a deeper level. She also wrote a book recently, Rust Atomics And Locks. I haven’t read it yet, but it looks useful.
Hey, you’re on a similar path to me. I’ve been on a Rust job for the past year.
Being a general-purpose programming language Rust can be used in a lot of contexts. The work I’m doing is all API server stuff, which I’m sure you already have a solid background in. There are some niches where Rust stands out that might be worth studying depending on your interest, but none of these are essential to Rust work generally.
nostd, and learning about controlling hardware.It looks like there is at least one work-in-pprogress implementation. I found a Hacker News comment that points to github.com/n0-computer/iroh
Yeah, that makes a lot of sense. If the thinking is that AI learning from others’ works is analogous to humans learning from others’ works then the logical conclusion is that AI is an independent creative, non-human entity. And there is precedent that works created by non-humans cannot be copyrighted. (I’m guessing this is what you are thinking, I just wanted to think it out for myself.)
I’ve been thinking about this issue as two opposing viewpoints:
The logic-in-a-vacuum viewpoint says that AI learning from others’ works is analogous to humans learning from others works. If one is not restricted by copyright, neither should the other be.
The pragmatic viewpoint says that AI imperils human creators, and it’s beneficial to society to put restrictions on its use.
I think historically that kind of pragmatic viewpoint has been steamrolled by the utility of a new technology. But maybe if AI work is not copyrightable that could help somewhat to mitigate screwing people over.
That sounds like a good learning project to me. I think there are two approaches you might take: web scraping, or an API client.
My guess is that web scraping might be easier for getting started because scrapers are easy to set up, and you can find very good documentation. In that case I think Perl is a reasonable choice of language since you’re familiar with it, and I believe it has good scraping libraries. Personally I would go with Typescript since I’m familiar with it, it’s not hard (relatively speaking) to get started with, and I find static type checking helpful for guiding one to a correctly working program.
OTOH if you opt to make a Lemmy API client I think the best language choices are Typescript or Rust because that’s what Lemmy is written in. So you can import the existing API client code. Much as I love Rust, it has a steeper learning curve so I would suggest going with Typescript. The main difficulty with this option is that you might not find much documentation on how to write a custom Lemmy client.
Whatever you choose I find it very helpful to set up LSP integration in vim for whatever language you use, especially if you’re using a statically type-checked language. I’ll be a snob for just a second and say that now that programming support has generally moved to the portable LSP model the difference between vim+LSP and an IDE is that the IDE has a worse editor and a worse integrated terminal.
I pretty much always use list/iterator combinators (map, filter, flat_map, reduce), or recursion. I guess the choice is whether it is convenient to model the problem as an iterator. I think both options are safer than for loops because you avoid mutable variables.
In nearly every case the performance difference between the strategies doesn’t matter. If it does matter you can always change it once you’ve identified your bottlenecks through profiling. But if your language implements optimizations like tail call elimination to avoid stack build-up, or stream fusion / lazy iterators then you might not see performance benefits from a for loop anyway.
And there is also Nushell and similar projects. Nushell has a concept with the same purpose as jc where you can install Nushell frontend functions for familiar commands such that the frontends parse output into a structured format, and you also get Nushell auto-completions as part of the package. Some of those frontends are included by default.
As an example if you run ps you get output as a Nushell table where you can select columns, filter rows, etc. Or you can run ^ps to bypass the Nushell frontend and get the old output format.
Of course the trade-off is that Nushell wants to be your whole shell while jc drops into an existing shell.
I’m a fan! I don’t necessarily learn more than I would watching and reading at home. The main value for me is socializing and networking. Also I usually learn about some things I wouldn’t have sought out myself, but which are often interesting.

Good to hear!
Well if you want to try another avenue, I’ve read about implementing self-referential structs using Pin.
There’s a discussion here, https://blog.cloudflare.com/pin-and-unpin-in-rust/
There’s a deep dive on pins here, but I don’t remember if it addresses self-referential types: https://fasterthanli.me/articles/pin-and-suffering
Oh I’m sorry! I messed up my test case so it only looked like the block fixed things.
Did you try adding the block like I suggested? I reproduced the same error that you are seeing, and verified in my playground snippet that the block fixes the problem.
It’s ok that query_map references pstmt. Isolating pstmt in a block causes it to be dropped at the end of the block while rec_iter continues to live. I think that might be thanks to temporary lifetime extension or something.
Ok I have a simple solution for you. What you need to do is to produce rec_iter in such a way that pstmt is dropped at the same time. You can do that by creating and calling pstmt in a block like this:
let rec_iter = {
let mut pstmt = conn.prepare(sql.as_str())?;
pstmt.query_map(/* ... */)?
};
Here is a Rust Playground example
I’m glad you found a workaround. I didn’t want to be defeated by the callback idea that I had yesterday so I worked on it some more and came up with a similar-but-different solution where ZnsMaker stores pstmt paired with a closure that borrows it. This is again a simplified version of your code that is self-contained:
The closure solution avoids the need to pass conn to make_stream. I don’t know if it would fix the new borrowing error that you got since I did not reproduce that error. But I think it might.
Does znsstream need to outlive znsm? If so I think my solution solves the problem. Does znsstream need to outlive conn? That would be more complicated.
Edit: Oh! You don’t need to put both the pstmt and a closure in ZnsMaker. Instead you can just store a closure if you move ownership of pstmt into the closure. That ensures that pstmt lives as long as the function that produces the iterator that you want:
Edit: Lol you don’t need ZnsMaker after all. See my other top-level comment. I learned some things working on this, so time well spent IMO.
Well I’m curious to know what solutions there are to this. But I did reduce your problem to a smaller, self-contained example:
struct ZKNoteStream<'a, T> {
rec_iter: Box + 'a>,
}
struct BorrowedThing(Vec);
impl BorrowedThing {
fn prepare(&self) -> IterProducer<'_> {
IterProducer(&self.0)
}
}
struct IterProducer<'a>(&'a Vec);
impl<'a> IterProducer<'a> {
fn query_map(&self) -> impl Iterator {
self.0.into_iter()
}
}
fn test(conn: &BorrowedThing) -> ZKNoteStream<'_, &String> {
let pstmt = conn.prepare();
let rec_iter = pstmt.query_map();
ZKNoteStream { // cannot return value referencing local variable `pstmt`
rec_iter: Box::new(rec_iter),
}
}
Edit: Wow, that code block came out mangled. Here is a Rust Playground link
I ran into a similar problem yesterday, but it was a case where I had control over all the code. What I did was the equivalent of changing query_map so that instead of taking a reference to its receiver, it takes ownership.
My thinking at the moment is that you may need to modify ZKNoteStream so that instead of containing the resulting iterator it contains pstmt, maybe paired with a function takes pstmt as an argument and returns the iterator. It seems like you should be able to create an FnOnce closure with a move keyword that moves ownership of pstmt into that closure, which you could then store in ZKNoteStream. But I’m not able to make that happen right now.
That’s a very nice one! I also enjoy programming ligatures.
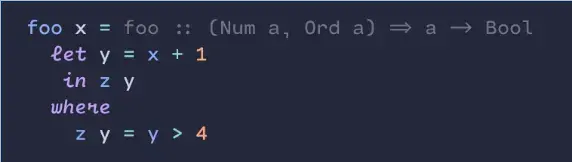
I use Cartograph CF. I like to use the handwriting style for built-in keywords. Those are common enough that I identify them by shape. The loopy handwriting helps me to skim over the keywords to focus on the words that are specific to each piece of code.
I wish more monospace fonts would use the “m” style from Ubuntu Mono. The middle leg is shortened which makes the glyph look less crowded.

Yes, I like your explanations and I agree that’s the way to think about it. But either way you have some special exceptions because main.rs maps to crate instead of to crate::main, and a/mod.rs maps to crate::a instead of to crate::a::mod. I know that’s the same thing you said, but I think it’s worth emphasizing that the very first file you work with is one of the exceptions which makes it harder to see the general rule. It works just the way it should; but I sympathize with anyone getting started who hasn’t internalized the special and general rules yet.
It scrolls smoothly, it doesn’t snap line by line. Although once the scroll animation is complete the final positions of lines and columns do end up aligned to a grid.
Neovim (as opposed to Vim) is not limited to terminal rendering. It’s designed to be a UI-agnostic backend. It happens that the default frontend runs in a terminal.